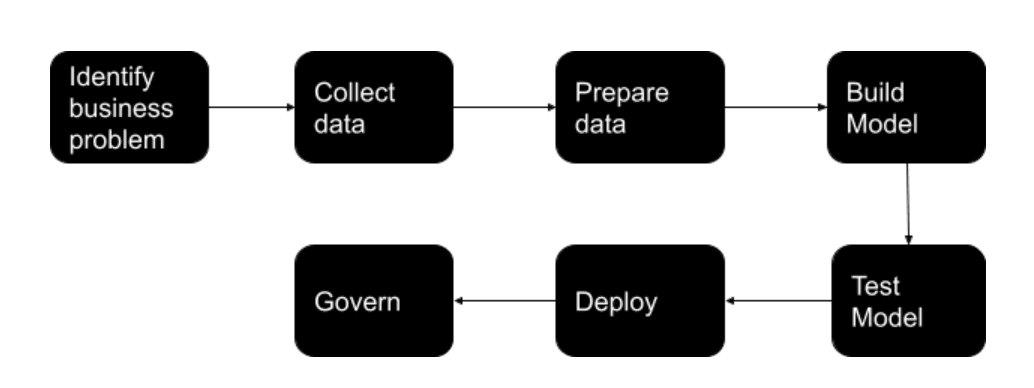
Overview of steps to develope a machine learning model
When you hear the words machine learning model, you probably think of face recognition, robotics or self-driving cars. But it’s so much more than that. You don’t have to be inventing the next big thing to leverage the power of machine learning in your business. In fact, you should be considering all the ways machine learning could work for you today.
Machine learning is not a way to solve the problems you’re already familiar with. It’s a way to solve new problems, business issues and tasks with data-driven predictions. To understand how you can apply machine learning, you need to first understand how it works. Let’s start by training a machine learning model.
Simple definition
Before getting deep into ML, let’s start with a basic definition. We have seen many complex definitions, but the one I find most impactful is also one of the simplest: Machine learning “gives computers the ability to learn without being explicitly programmed” (Arthur Samuel, 1959).
ML started in the ’50s and has risen and fallen in fashion over the years. However, ML is in its prime now thanks to the popularity of Cloud technologies.
Cloud enables ML to ingest and compute enormous amounts of data, allowing it to be more powerful. Additionally, new Cloud services allow ML to be much more accessible than previously known.
The predictive features of ML allow it to be highly useful in things like fraud detection, customer services, energy production, healthcare, security, manufacturing, and many others.
Step 1: Identification Of The Business Problem
So, in the first step of your model development, define the business problem you are looking to solve. At this stage, you need to ask the following questions.
- What results are you expecting from the process?
- What processes are in use to solve this problem?
- How do you see AI improving the current process?
- What are the KPIs that will help you track progress?
- What resources will be required?
- How do you break down the problem into iterative sprints?
Once you have answers to the above questions, you can then identify how you can solve the problem using AI. Generally, your business problem might fall in one of the below categories.
- Classification: As the name suggests, classification helps you to categorize something into type A or type B. You can use this to classify more than two types as well(called multi-class classification).
- Regression: Regression helps you to predict a definite number for a defined parameter. For example, predicting the number of COVID-19 cases in a particular period in the future, predicting the demand for your product during the holiday season, etc.
- Recommendation: Recommendation analyzes past data and identifies patterns. It can recommend your next purchase on a retail site, a video based on the topics you like, etc.
These are some of the basic questions you need to answer. You can add more questions here depending on your business objective. But the focus should be on business objectives and how AI can help achieve them.
Step 2: Identifying And Collecting Data
Identification of data is one of the most important steps in AI model development. Since machine learning models are only as accurate as the data fed to them, it becomes crucial to identify the right data to ensure model accuracy and relevance.
At this stage, you will have to ask questions like:
- What data is required to solve the business problem – customer data, inventory data, etc.
- What quantity of data is required?
- Do you have enough data to build the model?
- Do you need additional data to augment current data?
- How is the data collected and where is it stored?
- Can you use pre-trained data?
In addition to these questions, you will have to consider whether your model will operate in real-time. If your model is to function in real-time, you will need to create data pipelines to feed the model.
You will also have to consider what form of data is required to build the model. The following are the most common formats in which data is used.
Structured Data: The data will be in the form of rows and columns like a spreadsheet, customer database, inventory database, etc.
Unstructured Data: This type of data cannot be put into rows and columns(or a structure, hence the name). Examples include images, large quantities of text data, videos, etc.
Static Data: This is the historical data that does not change. Consider your call history, previous sales data, etc.
Streaming Data: This data keeps changing continuously, usually in real-time. Examples include your current website visitors.
Based on the problem definition, you need to identify the most relevant data and make it accessible to the model.
Step 3: Preparing The Data
This step is the most time-consuming in the entire model building process. Data scientists and ML engineers tend to spend around 80% of the AI model development time in this stage. The explanation is straightforward – model accuracy majorly depends on the data quality. You will have to avoid the “garbage in, garbage out” situation here.
Data preparation depends on what kind of data you need. The data collected in the previous step need not be in the same form, the same quality, or the same quantity as required. ML engineers spend a significant amount of time cleaning the data and transforming it into the required format. This step also involves segmenting the data into training, testing, and validation data sets.
Some of the things you need to consider at this stage include:
- Transforming the data into the required format
- Clean the data set for erroneous and irrelevant data
- Enhance and augment the data set if the quantity is low
Step 4: Model Building And Training
At this step, you have gathered all the requirements to build your machine learning model. The stage is all set and now the solution modeling begins.
In this stage, ML engineers define the features of the model. Some of the factors to consider here are:
- Use the same features for training and testing the model. Incoherence in the data at these two stages will lead to inaccurate results once the model is deployed in the real world.
- Consider working with Subject Matter Experts. SMEs are well equipped to direct you on what features would be necessary for a model. They will help you reduce the time in reiterating the models and give you a head start in creating accurate models.
- Be wary of the curse of dimensionality, which refers to using multiple features that might be irrelevant to the model. If you are using unnecessary features, then the model accuracy takes a dip.
Once you define the features, the next step is to choose the most suitable algorithm. Consider model interpretability when selecting an algorithm. You do not want to end up with a model whose predictions and decisions would be hard to explain.
Upon selecting the appropriate algorithm and building a model, you will have to test it with the training data. Remember, the model will not give the expected result in the first go. You will have to tune the hyperparameters, change the number of trees of a random forest, or change the number of layers in a neural network. At this stage, you can also use pre-trained models and reuse them to build a new model.
Each iteration of the model should ideally be versioned so that you can monitor its output easily.
Step 5: Model Testing
You train and tune the model using the training and the validation data sets respectively. However, the model would mostly behave differently when deployed in the real world, which is fine.
The main objective of this step is to minimize the change in model behavior upon its deployment in the real world. For this purpose, multiple experiments are carried out on the model using all three data sets – training, validation, and testing.
In case your model performs poorly on the training data, you will have to improve the model. You can do it by selecting a better algorithm, increasing the quality of data, or feeding more data to the model.
If your model does not perform well on testing data, then the model might be unable to extend the algorithm. There might be the issue of overfitting where the model is too closely fit with a limited number of data points. The best solution then would be to add more data to the model.
This stage involves carrying out multiple experiments on the model to bring out its best abilities and minimize the changes it undergoes post-deployment.
Step 6: Model Deployment
Once you test your model with different datasets, you will have to validate model performance using the business parameters defined in Step 1. Analyze whether the KPIs and the business objective of the model are achieved. In case the set parameters are not met, consider changing the model or improving the quality and the quantity of the data.
Upon meeting all defined parameters, deploy the model into the intended infrastructure like the cloud, at the edge, or on-premises environment. However, before deployment you should consider the following points:
- Make sure you plant to continuously measure and monitor the model performance
- Define a baseline to measure future iterations of the model
- Keep iterating the model to improve model performance with the changing data
Conclusion
At iRender, we provide a fast, powerful and efficient solution for Deep Learning users with configuration packages from 1 to 6 GPUs RTX 3090 on both Windows and Ubuntu operating systems. In addition, we also have GPU configuration packages from 1 RTX 3090 and 6 x RTX 3090. With the 24/7 professional support service, the powerful, free, and convenient data storage and transferring tool – GPUhub Sync, along with an affordable cost, make your training process more efficient.
Register an account today to experience our service. Or contact us via WhatsApp: (+84) 912 785 500 for advice and support.
Thank you & Happy Training!
Source: datasciencecentral.com
Related Posts
The latest creative news from Cloud Computing for AI,